Ngày 1/12/2025, Mạng Tài nguyên Giáo dục
Mở Toàn cầu, khu vực châu Á - Thái bình dương dành cho
các sinh viên tốt nghiệp - GO-GN
ASIA PACIFIC (Global OER Graduate Network - Asia Pacific Hub), Đại
học KHXHNV – ĐHQG Hà Nội
đã tổ chức hội thảo tại Hà Nội với chủ đề
‘Cập nhật phong trào Mở tại Việt Nam từ góc nhìn
nghiên cứu và thực hành’.
Trong thời gian cả ngày hội thảo, các
diễn giả tham dự hội thảo từ nhiều trường đại học
khắp cả nước đã trình bày các tham luận về nghiên
cứu và thực hành trên nhiều khía cạnh của phong trào
Mở ở Việt Nam như Giáo dục Mở, Tài nguyên Giáo dục
Mở, Nghiên cứu Mở, AI (Nguồn) Mở, Cấp phép Mở, Xuất
bản Truy cập Mở, Sư phạm Mở, Dữ liệu Mở, Phần mềm
Nguồn Mở. Hội thảo cũng đã dành nhiều thời gian thảo
luận về những điểm mạnh, yếu, cơ hội và thách thức
của việc triển khai các hoạt động nghiên cứu và thực
hành Tài nguyên Giáo dục Mở tại các cơ sở giáo dục
trong bối cảnh chính
sách về Tài nguyên Giáo dục Mở đã được Chính phủ
ban hành; cũng như vai trò của GO-GN ASIA PACIFIC là gì
trong việc hỗ trợ các giáo viên và nhà nghiên cứu tại
các cơ sở giáo dục của họ để tăng cường cho việc
nghiên cứu và thực hành Mở nói chung, Tài nguyên Giáo
dục Mở nói riêng. Những người tham dự cũng thảo luận
về một vài ưu tiên quan trọng nhất cho cộng đồng
hướng tới các bước hành động tiếp theo trong vài năm
tới.
Hiệp hội các trường Cao đẳng Nghề
nghiệp Ngoài công lập Việt Nam - Văn phòng đại diện
tại thành phố Hồ Chí Minh; Viện nghiên cứu, Đào tạo
và Phát triển tài nguyên giáo dục mở (InOER) và Google
For Education Việt Nam tổ chức Tọa đàm ‘Xây dựng nhà
trường số dựa trên nền tảng năng lực số và ứng
dụng công nghệ 4.0, AI’ trong ngày 28/11/2025 tại Trường
Cao đẳng Công nghệ - Năng lượng Khánh Hòa.
Mô hình Ngôn ngữ Lớn
(LLM) cung cấp sức mạnh to lớn cho nhiều tác vụ khác
nhau, nhưng hiệu quả của chúng phụ thuộc vào chất
lượng của các lời nhắc. Bài viết trên blog này
tóm tắt các khía cạnh quan trọng của việc thiết kế
lời nhắc hiệu quả để tối đa hóa hiệu suất LLM.
Những cân nhắc chính khi thiết kế lời
nhắc
Tính cụ thể và rõ ràng: Cũng giống
như việc hướng dẫn con người, lời nhắc cần nêu rõ
kết quả mong muốn. Sự mơ hồ có thể dẫn đến kết
quả đầu ra không mong muốn hoặc không liên quan.
Đầu vào và đầu ra có cấu trúc:
Việc cấu trúc đầu vào bằng các định dạng như JSON
hoặc XML có thể cải thiện đáng kể khả năng hiểu và
xử lý thông tin của LLM. Tương tự, việc chỉ định
định dạng đầu ra mong muốn (ví dụ: danh sách, đoạn
văn hoặc đoạn mã) sẽ cải thiện tính liên quan của
phản hồi.
Dấu phân cách cho Cấu trúc Nâng cao:
Việc sử dụng các ký tự đặc biệt làm dấu phân cách
trong lời nhắc có thể làm rõ hơn cấu trúc và phân tách
các thành phần khác nhau, cải thiện khả năng hiểu của
mô hình.
Phân tích Nhiệm vụ cho các Hoạt động
Phức tạp: Thay vì trình bày LLM với một lời nhắc
duy nhất bao gồm nhiều nhiệm vụ, việc chia nhỏ các quy
trình phức tạp thành các nhiệm vụ con đơn giản hơn sẽ
cải thiện đáng kể tính rõ ràng và hiệu suất. Điều
này cho phép mô hình tập trung vào từng nhiệm vụ con
riêng lẻ, cuối cùng dẫn đến kết quả tổng thể chính
xác hơn.
Các Chiến lược Lời nhắc Nâng cao
Lời nhắc vài lần (Few-Shot Prompting):
Cung cấp cho LLM một vài ví dụ về các cặp đầu vào-đầu
ra mong muốn sẽ hướng dẫn nó tạo ra các phản hồi
chất lượng cao hơn bằng cách chứng minh mô hình dự
kiến. Tìm hiểu thêm về gợi ý vài lần tại
đây.
Lời nhắc theo Chuỗi tư duy
(Chain-of-Thought Prompting): Khuyến khích mô hình "suy
nghĩ từng bước" bằng cách gợi ý rõ ràng để chia
nhỏ các nhiệm vụ phức tạp thành các bước suy luận
trung gian giúp nâng cao khả năng giải quyết các vấn đề
đòi hỏi suy luận logic. Tìm hiểu thêm về lời nhắc
theo chuỗi tư duy tại
đây.
Lời nhắc Tái hành động: ReAct (Suy
luận + Hành động): Phương pháp này tập trung vào
việc khơi gợi suy luận nâng cao, lập kế hoạch và thậm
chí cả việc sử dụng công cụ từ LLM. Bằng cách cấu
trúc các lời nhắc để khuyến khích những khả năng
này, các nhà phát triển có thể mở khóa các ứng dụng
tinh vi và mạnh mẽ hơn. Tìm hiểu thêm về ReAct tại
đây.
Kết luận
Thiết kế lời
nhắc hiệu quả là yếu tố then chốt để khai thác tối
đa tiềm năng của LLM. Bằng cách tuân thủ các phương
pháp hay nhất như tính cụ thể, định dạng có cấu
trúc, phân tích nhiệm vụ và tận dụng các kỹ thuật
tiên tiến như lời nhắc ít lần, chuỗi tư duy và ReAct,
các nhà phát triển có thể cải thiện đáng kể chất
lượng, độ chính xác và độ phức tạp của kết quả
đầu ra được tạo ra bởi các LLM mạnh mẽ này.
Large Language
Models (LLMs) offer immense power for various tasks, but their
effectiveness hinges on the quality of the prompts. This blog post
summarize important aspects of designing effective prompts to
maximize LLM performance.
Key Considerations for Prompt
Design
Specificity
and Clarity: Just
like giving instructions to a human, prompts should clearly
articulate the desired outcome. Ambiguity can lead to unexpected or
irrelevant outputs.
Structured
Inputs and Outputs:
Structuring inputs using formats like JSON or XML can significantly
enhance an LLM's ability to understand and process information.
Similarly, specifying the desired output format (e.g., a list,
paragraph, or code snippet) improves response relevance.
Delimiters
for Enhanced Structure:
Utilizing special characters as delimiters within prompts can further
clarify the structure and segregate different elements, improving the
model's understanding.
Task
Decomposition for Complex Operations:
Instead of presenting LLMs with a monolithic prompt encompassing
multiple tasks, breaking down complex processes into simpler subtasks
significantly improves clarity and performance. This allows the model
to focus on each subtask individually, ultimately leading to a more
accurate overall outcome.
Advanced
Prompting Strategies
Few-Shot
Prompting:
Providing the LLM with a few examples of desired input-output pairs
guides it towards generating higher-quality responses by
demonstrating the expected pattern. Learn more about few-shot
prompting here.
Chain-of-Thought
Prompting:
Encouraging the model to "think step-by-step" by explicitly
prompting it to break down complex tasks into intermediate reasoning
steps enhances its ability to solve problems that require logical
deduction. Learn more about chain-of-thought prompting here.
ReAct
(Reason + Act):
This method focuses on eliciting advanced reasoning, planning, and
even tool use from the LLM. By structuring prompts to encourage these
capabilities, developers can unlock more sophisticated and powerful
applications. Learn more about ReAct here.
Conclusion
Effective prompt
design is crucial for harnessing the full potential of LLMs. By
adhering to best practices like specificity, structured formatting,
task decomposition, and leveraging advanced techniques like few-shot,
chain-of-thought, and ReAct prompting, developers can significantly
improve the quality, accuracy, and complexity of outputs generated by
these powerful LLMs.
Hiệp hội Giáo dục Nghề nghiệp và Nghề
Công tác Xã hội Việt Nam - Văn phòng đại diện tại
thành phố Hồ Chí Minh; Viện nghiên cứu và Đào tạo và
Phát triển tài nguyên giáo dục mở (InOER) tổ chức Tọa
đàm ‘Chuyển đổi số và trí tuệ nhân tạo’ trong
ngày 26/11/2025 tại Trường Cao đẳng Lào Cai.
Các tác nhân đòi hỏi 3 năng lực cơ bản
để xử lý hiệu quả các nhiệm vụ phức tạp: khả
năng lập kế hoạch, sử dụng công cụ, và quản lý bộ
nhớ. Hãy cùng tìm hiểu cách các thành phần này hoạt
động cùng nhau để tạo ra các tác
nhân AI có chức năng.
Lập kế
hoạch: Bộ não của tác nhân
Cốt lõi của bất kỳ tác nhân AI hiệu
quả nào là khả năng lập kế hoạch, được hỗ trợ
bởi các mô hình ngôn ngữ lớn (LLM). Các LLM hiện đại
cho phép một số chức năng lập kế hoạch quan trọng:
Phân tích nhiệm vụ thông qua suy luận
chuỗi suy nghĩ
Tự phản ánh về các hành động và
thông tin trong quá khứ
Học tập thích ứng để cải thiện
các quyết định trong tương lai
Phân tích có phản biện tiến độ
hiện tại
Mặc dù khả năng lập kế hoạch của LLM
hiện tại chưa hoàn hảo, nhưng chúng rất cần thiết để
hoàn thành nhiệm vụ. Nếu không có khả năng lập kế
hoạch mạnh mẽ, một tác nhân không thể tự động hóa
hiệu quả các tác vụ phức tạp, điều này làm mất đi
mục đích chính của nó.
Sử dụng công cụ: Mở rộng khả năng
của tác nhân
Thành phần quan trọng thứ hai là khả
năng tương tác của tác nhân với các công cụ bên ngoài.
Một tác nhân được thiết kế tốt không chỉ phải có
quyền truy cập vào nhiều công cụ khác nhau mà còn phải
hiểu khi nào và cách sử dụng chúng một cách phù hợp.
Các công cụ phổ biến bao gồm:
Trình thông dịch mã và môi trường
thực thi
Tiện ích tìm kiếm và thu thập dữ
liệu trên web
Máy tính toán học
Hệ thống tạo hình ảnh
Các công cụ này cho phép tác nhân thực
hiện các hành động đã lên kế hoạch, biến các chiến
lược trừu tượng thành kết quả cụ thể. Khả năng
hiểu được lựa chọn công cụ và thời điểm của LLM
là rất quan trọng để xử lý các tác vụ phức tạp một
cách hiệu quả.
Hệ thống bộ nhớ: Lưu giữ và sử
dụng thông tin
Thành phần thiết yếu thứ ba là quản lý
bộ nhớ, có hai dạng chính:
Bộ nhớ (làm việc) ngắn hạn
Hoạt động như một bộ nhớ đệm
cho ngữ cảnh tức thời
Cho phép học tập theo ngữ cảnh
Đủ cho việc hoàn thành hầu hết
các nhiệm vụ
Giúp duy trì tính liên tục trong quá
trình lặp lại nhiệm vụ
Bộ nhớ dài hạn
Được triển khai thông qua các kho
lưu trữ vectơ bên ngoài
Cho phép truy xuất nhanh chóng thông
tin lịch sử
Có giá trị cho việc hoàn thành nhiệm
vụ trong tương lai
Ít được triển khai hơn nhưng có
khả năng rất quan trọng cho các phát triển trong tương
lai
Hệ thống bộ nhớ cho phép các tác nhân
lưu trữ và truy xuất thông tin thu thập được từ các
công cụ bên ngoài, cho phép cải tiến liên tục và xây
dựng dựa trên kiến thức trước đó.
Sự đồng vận giữa
khả năng lập kế hoạch, sử dụng công cụ và hệ thống
bộ nhớ tạo nên nền tảng cho các tác nhân AI hiệu quả.
Mặc dù mỗi thành phần đều có những hạn chế hiện
tại, việc hiểu rõ các khả năng cốt lõi này là rất
quan trọng để phát triển và làm việc với các tác nhân
AI. Khi công nghệ phát triển, chúng ta có thể thấy các
loại bộ nhớ và khả năng mới xuất hiện, nhưng ba trụ
cột này có thể sẽ vẫn là nền tảng cơ bản cho kiến
trúc tác nhân AI.
AI agents
require three fundamental capabilities to effectively tackle complex
tasks: planning abilities, tool utilization, and memory management.
Let's dive into how these components work together to create
functional AI agents.
Planning:
The Brain of the Agent
At the core of
any effective AI agent is its planning capability, powered by large
language models (LLMs). Modern LLMs enable several crucial planning
functions:
Task
decomposition through chain-of-thought reasoning
Self-reflection
on past actions and information
Adaptive
learning to improve future decisions
Critical
analysis of current progress
While current
LLM planning capabilities aren't perfect, they're essential for task
completion. Without robust planning abilities, an agent cannot
effectively automate complex tasks, which defeats its primary
purpose.
Tool Utilization: Extending the
Agent's Capabilities
The second
critical component is an agent's ability to interface with external
tools. A well-designed agent must not only have access to various
tools but also understand when and how to use them appropriately.
Common tools include:
Code
interpreters and execution environments
Web search
and scraping utilities
Mathematical
calculators
Image
generation systems
These tools
enable the agent to execute its planned actions, turning abstract
strategies into concrete results. The LLM's ability to understand
tool selection and timing is crucial for handling complex tasks
effectively.
Memory Systems: Retaining and
Utilizing Information
The third
essential component is memory management, which comes in two primary
forms:
Short-term
(Working) Memory
Functions
as a buffer for immediate context
Enables
in-context learning
Sufficient
for most task completions
Helps
maintain continuity during task iteration
Long-term
Memory
Implemented
through external vector stores
Enables
fast retrieval of historical information
Valuable
for future task completion
Less
commonly implemented but potentially crucial for future
developments
Memory systems
allow agents to store and retrieve information gathered from external
tools, enabling iterative improvement and building upon previous
knowledge.
The synergy
between planning capabilities, tool utilization, and memory systems
forms the foundation of effective AI agents. While each component has
its current limitations, understanding these core capabilities is
crucial for developing and working with AI agents. As the technology
evolves, we may see new memory types and capabilities emerge, but
these three pillars will likely remain fundamental to AI agent
architecture.
Hiệp hội Giáo dục Nghề nghiệp và Nghề Công tác Xã hội Việt Nam - Văn phòng đại diện tại thành phố Hồ Chí Minh; Viện nghiên cứu, Đào tạo
và Phát triển tài nguyên giáo dục mở (InOER) và Google
For Education Việt Nam tổ chức Tọa đàm ‘Xây dựng nhà
trường số dựa trên nền tảng năng lực số và ứng
dụng công nghệ 4.0, AI’ trong ngày 24/11/2025 tại Trường
Cao đẳng Công nghệ - Năng lượng Khánh Hòa.
Các tác nhân đang cách mạng hóa cách thức
chúng ta tiếp cận các nhiệm vụ phức tạp, tận dụng
sức mạnh của các mô hình ngôn ngữ lớn (LLM) để làm
việc nhân danh chúng ta và đạt được những kết quả
đáng chú ý. Trong hướng dẫn này,
chúng ta sẽ đi sâu vào những nguyên tắc cơ bản của
các tác nhân AI, khám phá khả năng, mô hình thiết kế và
các ứng dụng tiềm năng của chúng.
Tác nhân là gì?
Trong hướng dẫn này,
chúng tôi tham chiếu tới một tác nhân như một hệ thống
LLM được thiết kế để hành động và giải quyết các
nhiệm vụ phức tạp một cách tự chủ. Không giống như
các LLM truyền thống, các tác nhân AI đi vượt ra khỏi
sự tạo sinh văn bản đơn giản. Chúng được trang bị
với các năng lực bổ sung, bao gồm:
Lập kế hoạch và phản ánh:
Các tác nhân AI có thể phân tích vấn đề, chia nhỏ
thành các bước và điều chỉnh cách tiếp cận dựa
trên thông tin mới.
Truy cập công cụ: Chúng có thể
tương tác với các công cụ và tài nguyên bên ngoài,
chẳng hạn như cơ sở dữ liệu, giao diện lập trình
ứng dụng (API) và các ứng dụng phần mềm, để thu
thập thông tin và thực hiện hành động.
Bộ nhớ: Các tác nhân AI có thể
lưu trữ và truy xuất thông tin, cho phép chúng học hỏi
từ kinh nghiệm trong quá khứ và đưa ra quyết định
sáng suốt hơn.
Bài giảng này thảo luận về khái niệm
tác nhân AI và tầm quan trọng của chúng trong lĩnh vực
trí tuệ nhân tạo.
Tại sao nên xây dựng với các tác
nhân?
Mặc dù các mô hình ngôn ngữ lớn (LLM)
vượt trội trong các nhiệm vụ đơn giản, hẹp như dịch
thuật hoặc tạo email, nhưng chúng lại kém hiệu quả khi
xử lý các nhiệm vụ phức tạp, rộng hơn, đòi hỏi
nhiều bước, lập kế hoạch và lập luận. Những nhiệm
vụ phức tạp này thường đòi hỏi phải truy cập vào
các công cụ và thông tin bên ngoài nằm ngoài cơ sở kiến
thức của LLM.
Ví dụ: việc phát triển
chiến lược tiếp thị có thể bao gồm việc nghiên cứu
đối thủ cạnh tranh, phân tích xu hướng thị trường và
truy cập dữ liệu cụ thể của công ty. Những hành động
này đòi hỏi thông tin thực tế, những hiểu biết mới
nhất và dữ liệu nội bộ của công ty, những thứ mà
một LLM độc lập có thể không có quyền truy cập.
Các tác nhân AI thu hẹp khoảng cách này
bằng cách kết hợp các khả năng của LLM với các tính
năng bổ sung như bộ nhớ, lập kế hoạch và các công cụ
bên ngoài.
Bằng cách tận dụng những khả năng này,
các tác nhân AI có thể giải quyết hiệu quả các nhiệm
vụ phức tạp như:
Phát triển chiến lược tiếp thị
Lên kế hoạch sự kiện
Cung cấp hỗ trợ khách hàng
Các trường hợp sử dụng phổ biến
của tác nhân AI
Dưới đây là danh sách (chưa đầy đủ)
các trường hợp sử dụng phổ biến mà tác nhân đang
được áp dụng trong ngành:
Hệ thống đề xuất: Cá nhân
hóa đề xuất về sản phẩm, dịch vụ hoặc nội dung.
Hệ thống hỗ trợ khách hàng:
Xử lý yêu cầu, giải quyết vấn đề & cung cấp hỗ
trợ.
Nghiên cứu: Tiến hành điều
tra chuyên sâu trên nhiều lĩnh vực khác nhau, chẳng hạn
như pháp lý, tài chính và y tế.
Ứng dụng thương mại điện tử:
Tạo điều kiện thuận lợi cho trải nghiệm mua sắm
trực tuyến, quản lý đơn hàng và cung cấp các đề
xuất được cá nhân hóa.
Đặt chỗ: Hỗ trợ sắp xếp
chuyến đi và lập kế hoạch sự kiện.
Báo cáo: Phân tích lượng lớn
dữ liệu và tạo báo cáo toàn diện.
Phân tích tài chính: Phân tích
xu hướng thị trường, đánh giá dữ liệu tài chính và
tạo báo cáo với tốc độ và độ chính xác chưa từng
có.
Agents are
revolutionizing the way we approach complex tasks, leveraging the
power of large language models (LLMs) to work on our behalf and
achieve remarkable results. In this guide we will dive into the
fundamentals of AI agents, exploring their capabilities, design
patterns, and potential applications.
What is an
Agent?
In this guide,
we refer to an agent as an LLM-powered system designed to take
actions and solve complex tasks autonomously. Unlike traditional
LLMs, AI agents go beyond simple text generation. They are equipped
with additional capabilities, including:
Planning
and reflection: AI
agents can analyze a problem, break it down into steps, and adjust
their approach based on new information.
Tool
access: They can
interact with external tools and resources, such as databases, APIs,
and software applications, to gather information and execute
actions.
Memory:
AI agents can store and retrieve information, allowing them to learn
from past experiences and make more informed decisions.
This lecture
discusses the concept of AI agents and their significance in the
realm of artificial intelligence.
Why
build with Agents?
While large
language models (LLMs) excel at simple, narrow tasks like translation
or email generation, they fall short when dealing with complex,
broader tasks that require multiple steps, planning, and reasoning.
These complex tasks often necessitate access to external tools and
information beyond the LLM's knowledge base.
For example,
developing a marketing strategy might involve researching
competitors, analyzing market trends, and accessing company-specific
data. These actions necessitate real-world information, the latest
insights, and internal company data, which a standalone LLM might not
have access to.
AI agents bridge
this gap by combining the capabilities of LLMs with additional
features such as memory, planning, and external tools.
By leveraging
these abilities, AI agents can effectively tackle complex tasks like:
Developing
marketing strategies
Planning
events
Providing
customer support
Common
Use Cases for AI Agents
Here is a
non-exhaustive list of common use cases where agents are being
applied in the industry:
Recommendation
systems:
Personalizing suggestions for products, services, or content.
Customer
support systems:
Handling inquiries, resolving issues, and providing assistance.
Research:
Conducting in-depth investigations across various domains, such as
legal, finance, and health.
Zhang
và cộng sự (2023) gần đây đã đề xuất một phương
pháp gợi ý chuỗi tư duy - CoT (Chain-of-thought) đa phương
thức. CoT truyền thống tập trung vào phương thức ngôn
ngữ. Ngược lại, CoT đa phương thức
kết hợp văn bản và hình ảnh vào một khuôn khổ hai
giai đoạn. Bước đầu tiên liên quan đến việc
tạo ra cơ sở lý luận dựa trên thông tin đa phương
thức. Tiếp theo là giai đoạn thứ hai, suy luận câu trả
lời, tận dụng các cơ sở lý luận mang tính thông tin
được tạo ra.
Mô hình CoT đa phương thức (1B) vượt
trội hơn GPT-3.5 trên tiêu chuẩn ScienceQA.
Zhang
et al. (2023) recently proposed a multimodal chain-of-thought
prompting approach. Traditional CoT focuses on the language modality.
In contrast, Multimodal CoT incorporates text and vision into a
two-stage framework. The first step involves rationale generation
based on multimodal information. This is followed by the second
phase, answer inference, which leverages the informative generated
rationales.
The multimodal
CoT model (1B) outperforms GPT-3.5 on the ScienceQA benchmark.
Phản xạ là một khuôn khổ để củng cố các tác nhân dựa trên ngôn ngữ thông qua phản hồi ngôn ngữ. Theo Shinn và cộng sự (2023),
"Phản xạ là một mô hình mới cho việc củng cố 'bằng lời nói', tham số
hóa chính sách thành mã hóa bộ nhớ của tác nhân kết hợp với các tham số
LLM được lựa chọn."
Ở cấp độ cao, Phản xạ chuyển đổi phản hồi (dạng ngôn
ngữ tự do hoặc dạng vô hướng) từ môi trường thành phản hồi ngôn ngữ, còn
được gọi là tự phản xạ (self-reflection), được
cung cấp làm bối cảnh cho tác nhân LLM trong hành động tiếp theo. Điều
này giúp tác nhân học hỏi nhanh chóng và hiệu quả từ những sai lầm trước
đó, dẫn đến cải thiện hiệu suất trong nhiều tác vụ nâng cao.
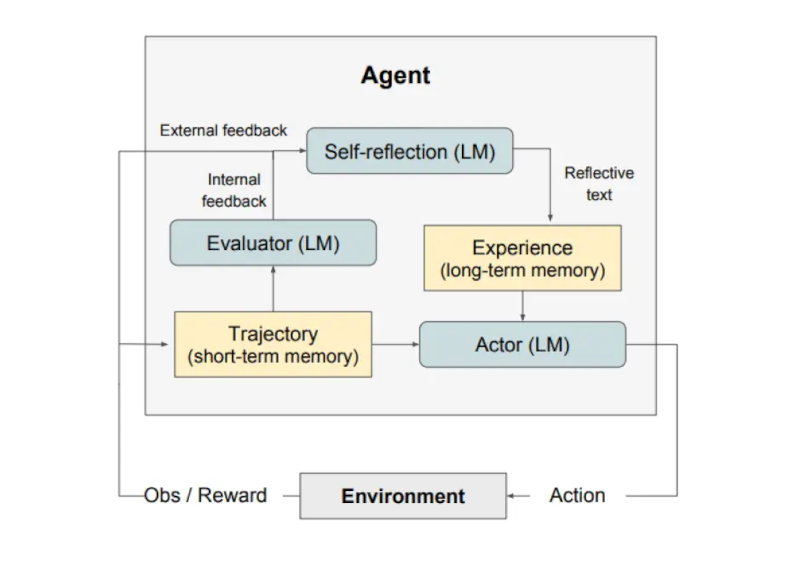
Như được minh họa trong hình ở trên, Reflexion gồm 3 mô hình riêng biệt:
Một Actor (Người hành động): Tạo văn bản và
hành động dựa trên các quan sát trạng thái. Actor thực hiện một hành
động trong môi trường và nhận được một quan sát, từ đó tạo ra một quỹ
đạo. Chuỗi Tư duy - CoT (Chain-of-Thought) và ReAct được sử dụng làm mô
hình Actor. Một thành phần bộ nhớ cũng được thêm vào để cung cấp thêm
ngữ cảnh cho tác nhân.
Một Evaluator (Người đánh giá):
Chấm điểm các kết quả đầu ra do Actor tạo ra. Cụ thể, nó lấy đầu vào là
một quỹ đạo đã được tạo ra (còn được gọi là bộ nhớ ngắn hạn) và đưa ra
điểm thưởng. Các hàm thưởng khác nhau được sử dụng tùy thuộc vào nhiệm
vụ (LLM và phương pháp tìm kiếm dựa trên quy tắc được sử dụng cho các
nhiệm vụ ra quyết định).
Tự phản ánh (Self-Reflection): Tạo ra
các tín hiệu củng cố bằng lời nói để hỗ trợ Actor trong việc tự cải
thiện. Vai trò này được thực hiện bởi một LLM và cung cấp phản hồi có
giá trị cho các thử nghiệm trong tương lai. Để tạo ra phản hồi cụ thể và
có liên quan, điều cũng được lưu trữ trong bộ nhớ, mô hình tự phản ánh
sử dụng tín hiệu thưởng, quỹ đạo hiện tại và bộ nhớ liên tục của nó.
Những kinh nghiệm này (được lưu trữ trong bộ nhớ dài hạn) được tác nhân
tận dụng để cải thiện nhanh chóng quá trình ra quyết định.
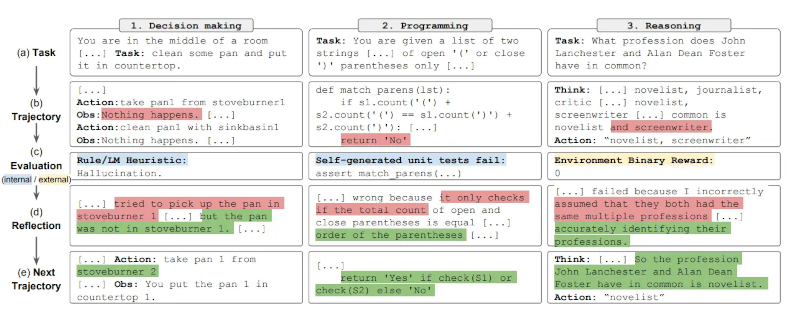
Tóm lại, các bước chính của quy trình Reflexion là a)
xác định một nhiệm vụ, b) tạo một quỹ đạo, c) đánh giá, d) thực hiện
phản ánh, và e) tạo quỹ đạo tiếp theo. Hình dưới đây minh họa các ví dụ
về cách một tác nhân Reflexion có thể học cách tối ưu hóa hành vi của
mình theo từng bước lặp để giải quyết các nhiệm vụ khác nhau như ra
quyết định, lập trình và suy luận. Reflexion mở rộng khuôn khổ ReAct
bằng cách giới thiệu các thành phần tự đánh giá, tự phản ánh và bộ nhớ.
Kết quả
Kết quả thử nghiệm chứng
minh rằng các tác nhân Reflexion cải thiện đáng kể hiệu suất trong các
tác vụ ra quyết định AlfWorld, các câu hỏi suy luận trong HotPotQA và
các tác vụ lập trình Python trên HumanEval.
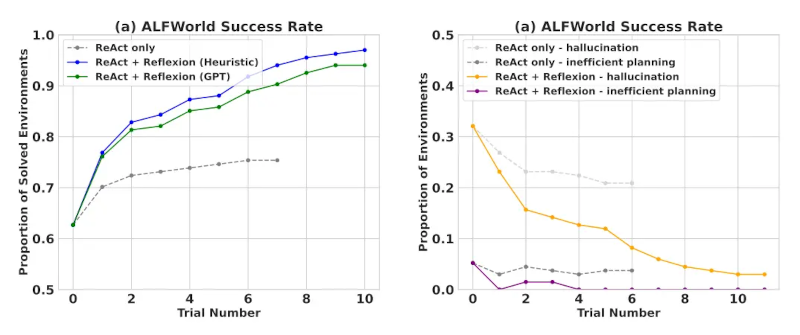
Khi được đánh giá trên
các tác vụ ra quyết định tuần tự (AlfWorld), ReAct + Reflexion vượt trội
hơn đáng kể so với ReAct khi hoàn thành 130/134 tác vụ bằng các kỹ
thuật tự đánh giá Heuristic và GPT để phân loại nhị phân.
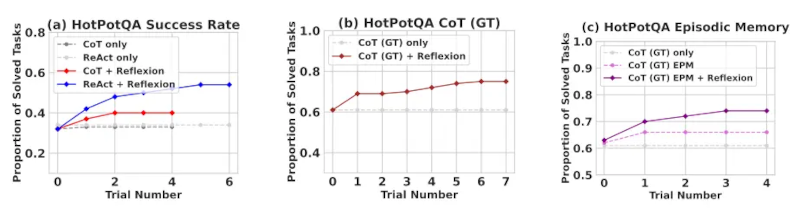
Reflexion vượt trội hơn hẳn so với tất cả các phương
pháp cơ bản qua nhiều bước học. Chỉ áp dụng cho suy luận và khi thêm bộ
nhớ theo giai đoạn bao gồm quỹ đạo gần nhất, Reflexion + CoT vượt trội
hơn so với việc chỉ áp dụng CoT và CoT kết hợp với bộ nhớ theo giai
đoạn.
Như tóm tắt trong bảng dưới đây, Reflexion nhìn chung
vượt trội hơn các phương pháp tiên tiến trước đây về viết mã Python và
Rust trên MBPP, HumanEval và Leetcode Hard.
Khi nào sử dụng Reflexion?
Reflexion phù hợp nhất cho các trường hợp sau:
Tác nhân cần học hỏi từ quá trình thử và sai:
Reflexion được thiết kế để giúp tác nhân cải thiện hiệu suất bằng cách
suy ngẫm về những sai lầm trong quá khứ và kết hợp kiến thức đó vào các
quyết định trong tương lai. Điều này làm cho nó phù hợp với các nhiệm vụ
mà tác nhân cần học hỏi thông qua quá trình thử và sai, chẳng hạn như
ra quyết định, suy luận và lập trình.
Các phương pháp học tăng cường - RL (Reinforcement Learning) truyền thống không thực tế:
Các phương pháp học tăng cường (RL) truyền thống thường yêu cầu dữ liệu
huấn luyện phong phú và tinh chỉnh mô hình tốn kém. Reflexion cung cấp
một giải pháp thay thế nhẹ nhàng, không yêu cầu tinh chỉnh mô hình ngôn
ngữ cơ bản, giúp nó hiệu quả hơn về mặt dữ liệu và tài nguyên tính toán.
Cần có phản hồi có sắc thái: Reflexion sử
dụng phản hồi bằng lời nói, có thể có sắc thái và cụ thể hơn so với phần
thưởng vô hướng được sử dụng trong RL truyền thống. Điều này cho phép
tác nhân hiểu rõ hơn về những sai lầm của mình và thực hiện các cải tiến
có mục tiêu hơn trong các lần thử tiếp theo.
Khả năng diễn giải và trí nhớ rõ ràng rất quan trọng:
Reflexion cung cấp một dạng trí nhớ theo giai đoạn dễ diễn giải và rõ
ràng hơn so với các phương pháp RL truyền thống. Quá trình tự phản ánh
của tác nhân được lưu trữ trong bộ nhớ, cho phép phân tích và hiểu rõ
hơn về quá trình học tập của nó.
Reflexion hiệu quả trong các tác vụ sau:
Ra quyết định tuần tự: Các tác nhân Reflexion
cải thiện hiệu suất của chúng trong các tác vụ AlfWorld, bao gồm việc
điều hướng qua nhiều môi trường khác nhau và hoàn thành các mục tiêu
nhiều bước.
Suy luận: Reflexion đã cải thiện hiệu suất
của các tác nhân trên HotPotQA, một tập dữ liệu trả lời câu hỏi yêu cầu
suy luận trên nhiều tài liệu.
Lập trình: Các tác nhân Reflexion viết mã tốt
hơn trên các điểm chuẩn như HumanEval và MBPP, đạt được kết quả tiên
tiến trong một số trường hợp.
Dưới đây là một số hạn chế của Reflexion:
Dựa vào khả năng tự đánh giá: Reflexion dựa
vào khả năng của tác nhân trong việc đánh giá chính xác hiệu suất của nó
và tạo ra các phản ánh tự phản ánh hữu ích. Điều này có thể là một
thách thức, đặc biệt là đối với các tác vụ phức tạp, nhưng dự kiến
Reflexion sẽ ngày càng tốt hơn theo thời gian khi các mô hình tiếp tục
cải thiện khả năng.
Hạn chế về bộ nhớ dài hạn: Reflexion sử dụng
cửa sổ trượt với dung lượng tối đa, nhưng đối với các tác vụ phức tạp
hơn, việc sử dụng các cấu trúc nâng cao như nhúng vector hoặc cơ sở dữ
liệu SQL có thể mang lại lợi thế.
Hạn chế về tạo mã: Phát triển hướng kiểm thử
có những hạn chế trong việc chỉ định các ánh xạ đầu vào-đầu ra chính xác
(ví dụ: hàm tạo không xác định và đầu ra hàm bị ảnh hưởng bởi phần
cứng).
Nguồn hình ảnh: Reflexion: Tác nhân Ngôn ngữ với Học Tăng cường Bằng Lời
Reflexion is a
framework to reinforce language-based agents through linguistic
feedback. According to Shinn
et al. (2023), "Reflexion is a new paradigm for ‘verbal‘
reinforcement that parameterizes a policy as an agent’s memory
encoding paired with a choice of LLM parameters."
At a high level,
Reflexion converts feedback (either free-form language or scalar)
from the environment into linguistic feedback, also referred to as
self-reflection,
which is provided as context for an LLM agent in the next episode.
This helps the agent rapidly and effectively learn from prior
mistakes leading to performance improvements on many advanced tasks.
As shown in the
figure above, Reflexion consists of three distinct models:
An
Actor: Generates
text and actions based on the state observations. The Actor takes an
action in an environment and receives an observation which results
in a trajectory. Chain-of-Thought
(CoT) and ReAct
are used as Actor models. A memory component is also added to
provide additional context to the agent.
An
Evaluator: Scores
outputs produced by the Actor. Concretely, it takes as input a
generated trajectory (also denoted as short-term memory) and outputs
a reward score. Different reward functions are used depending on the
task (LLMs and rule-based heuristics are used for decision-making
tasks).
Self-Reflection:
Generates verbal reinforcement cues to assist the Actor in
self-improvement. This role is achieved by an LLM and provides
valuable feedback for future trials. To generate specific and
relevant feedback, which is also stored in memory, the
self-reflection model makes use of the reward signal, the current
trajectory, and its persistent memory. These experiences (stored in
long-term memory) are leveraged by the agent to rapidly improve
decision-making.
In summary, the
key steps of the Reflexion process are a) define a task, b) generate
a trajectory, c) evaluate, d) perform reflection, and e) generate the
next trajectory. The figure below demonstrates examples of how a
Reflexion agent can learn to iteratively optimize its behavior to
solve various tasks such as decision-making, programming, and
reasoning. Reflexion extends the ReAct framework by introducing
self-evaluation, self-reflection and memory components.
Results
Experimental
results demonstrate that Reflexion agents significantly improve
performance on decision-making AlfWorld tasks, reasoning questions in
HotPotQA, and Python programming tasks on HumanEval.
When evaluated
on sequential decision-making (AlfWorld) tasks, ReAct + Reflexion
significantly outperforms ReAct by completing 130/134 tasks using
self-evaluation techniques of Heuristic and GPT for binary
classification.
Reflexion
significantly outperforms all baseline approaches over several
learning steps. For reasoning only and when adding an episodic memory
consisting of the most recent trajectory, Reflexion + CoT outperforms
CoT only and CoT with episodic memory, respectively.
As summarized in
the table below, Reflexion generally outperforms the previous
state-of-the-art approaches on Python and Rust code writing on MBPP,
HumanEval, and Leetcode Hard.
When
to Use Reflexion?
Reflexion is
best suited for the following:
An
agent needs to learn from trial and error:
Reflexion is designed to help agents improve their performance by
reflecting on past mistakes and incorporating that knowledge into
future decisions. This makes it well-suited for tasks where the
agent needs to learn through trial and error, such as
decision-making, reasoning, and programming.
Traditional
reinforcement learning methods are impractical:
Traditional reinforcement learning (RL) methods often require
extensive training data and expensive model fine-tuning. Reflexion
offers a lightweight alternative that doesn't require fine-tuning
the underlying language model, making it more efficient in terms of
data and compute resources.
Nuanced
feedback is required:
Reflexion utilizes verbal feedback, which can be more nuanced and
specific than scalar rewards used in traditional RL. This allows the
agent to better understand its mistakes and make more targeted
improvements in subsequent trials.
Interpretability
and explicit memory are important:
Reflexion provides a more interpretable and explicit form of
episodic memory compared to traditional RL methods. The agent's
self-reflections are stored in its memory, allowing for easier
analysis and understanding of its learning process.
Reflexion is
effective in the following tasks:
Sequential
decision-making:
Reflexion agents improve their performance in AlfWorld tasks, which
involve navigating through various environments and completing
multi-step objectives.
Reasoning:
Reflexion improved the performance of agents on HotPotQA, a
question-answering dataset that requires reasoning over multiple
documents.
Programming:
Reflexion agents write better code on benchmarks like HumanEval and
MBPP, achieving state-of-the-art results in some cases.
Here are some
limitations of Reflexion:
Reliance
on self-evaluation capabilities:
Reflexion relies on the agent's ability to accurately evaluate its
performance and generate useful self-reflections. This can be
challenging, especially for complex tasks but it's expected that
Reflexion gets better over time as models keep improving in
capabilities.
Long-term
memory constraints:
Reflexion makes use of a sliding window with maximum capacity but
for more complex tasks it may be advantageous to use advanced
structures such as vector embedding or SQL databases.
Code
generation limitations:
There are limitations to test-driven development in specifying
accurate input-output mappings (e.g., non-deterministic generator
function and function outputs influenced by hardware).
Yao và cộng sự, 2022
đã giới thiệu một khuôn khổ có tên ReAct, trong đó các mô hình ngôn ngữ
lớn - LLM (Large Language Model) được sử dụng để tạo ra cả dấu vết suy luận và các hành động cụ thể theo nhiệm vụ một cách đan xen.
Việc tạo ra dấu vết suy luận cho phép mô hình tạo ra,
theo dõi và cập nhật các kế hoạch hành động, và thậm chí xử lý các
trường hợp ngoại lệ. Bước hành động này cho phép giao tiếp và thu thập
thông tin từ các nguồn bên ngoài như cơ sở kiến thức hoặc môi trường.
Khuôn khổ ReAct có thể cho phép các LLM tương tác với
các công cụ bên ngoài để thu thập thêm thông tin, dẫn đến các phản hồi
đáng tin cậy và thực tế hơn.
Kết quả cho thấy ReAct có thể vượt trội hơn một số
nền tảng tiên tiến về ngôn ngữ và các nhiệm vụ ra quyết định. ReAct cũng
giúp cải thiện khả năng diễn giải và độ tin cậy của LLM đối với con
người. Nhìn chung, các tác giả nhận thấy rằng phương pháp tiếp cận tốt
nhất là sử dụng ReAct kết hợp với chuỗi tư duy - CoT (Chain-of-thought),
cho phép sử dụng cả kiến thức nội bộ và thông tin bên ngoài thu được
trong quá trình suy luận.
Cách thức hoạt động?
ReAct được lấy cảm hứng từ sự đồng vận giữa "hành
động" và "lý luận", cho phép con người học các nhiệm vụ mới và đưa ra
quyết định hoặc lý luận.
Phương pháp lời nhắc chuỗi tư duy (CoT) đã cho thấy
khả năng của LLM trong việc thực hiện các dấu vết suy luận để tạo ra câu
trả lời cho các câu hỏi liên quan đến số học và suy luận thông thường,
cùng với các nhiệm vụ khác (Wei và cộng sự, 2022).
Tuy nhiên, việc thiếu khả năng tiếp cận thế giới bên ngoài hoặc không
thể cập nhật kiến thức có thể dẫn đến các vấn đề như ảo giác sự thật và
lan truyền lỗi.
ReAct là một mô hình chung kết hợp suy luận và hành
động với LLM. ReAct gợi ý cho LLM tạo ra các dấu vết lý luận bằng lời
nói và hành động cho một nhiệm vụ. Điều này cho phép hệ thống thực hiện
việc suy luận động để tạo lập, duy trì và điều chỉnh các kế hoạch hành
động, đồng thời cho phép tương tác với môi trường bên ngoài (ví dụ:
Wikipedia) để kết hợp thông tin bổ sung vào suy luận. Hình dưới đây minh
họa một ví dụ về ReAct và các bước khác nhau liên quan để thực hiện trả
lời câu hỏi.
Trong ví dụ trên, chúng ta truyền một lời nhắc như câu hỏi sau đây từ HotpotQA:
Ngoài Apple Remote, còn có thiết bị nào khác có thể kiểm soát chương trình mà Apple Remote ban đầu được thiết kế để tương tác hay không? (Aside from the Apple Remote, what other devices can control the program Apple Remote was originally designed to interact with?)
Lưu ý rằng các ví dụ trong ngữ cảnh đó cũng được thêm
vào lời nhắc, nhưng chúng tôi loại trừ điều đó ở đây để đơn giản hóa.
Chúng ta có thể thấy rằng mô hình tạo ra các quỹ đạo giải quyết nhiệm vụ
(Suy nghĩ, Hành động). Quan sát tương ứng với quan sát từ môi trường
đang được tương tác (ví dụ: Công cụ tìm kiếm). Về bản chất, ReAct có thể
truy xuất thông tin để hỗ trợ suy luận, trong khi suy luận giúp xác
định mục tiêu cần truy xuất tiếp theo.
Lời nhắc ReAct
Để minh họa cách thức hoạt động của lời nhắc ReAct, hãy xem xét một ví dụ từ bài báo.
Bước đầu tiên là chọn các trường hợp từ tập huấn
luyện (ví dụ: HotPotQA) và tạo ra các quỹ đạo định dạng ReAct. Chúng
được sử dụng như các ví dụ mẫu trong các lời nhắc. Các quỹ đạo bao gồm
nhiều bước suy nghĩ-hành động-quan sát như được hiển thị trong hình
trên. Các suy nghĩ dạng tự do được sử dụng để hoàn thành các nhiệm vụ
khác nhau như phân tích câu hỏi, trích xuất thông tin, thực hiện suy
luận thông thường/số học, hướng dẫn việc tìm kiếm và tổng hợp câu trả
lời cuối cùng.
Sau đây là một ví dụ về hình thức của lời nhắc ReAct (lấy từ bài báo và rút gọn thành một ví dụ để đơn giản hơn):
Câu hỏi Phạm vi độ cao của khu vực mà phần phía đông của tạo núi Colorado kéo dài đến là bao nhiêu?Suy nghĩ 1 Tôi cần tìm kiếm tạo núi Colorado, tìm khu vực mà phần phía đông của tạo núi Colorado kéo dài đến, sau đó tìm phạm vi độ cao của khu vực đó.Hành động 1 Tìmkiếm[tạo núi Colorado]Quan sát 1 Tạo núi Colorado là một giai đoạn kiến tạo núi (tạo núi) ở Colorado và các khu vực xung quanh.Suy nghĩ 2 Nó không đề cập đến phần phía đông. Vì vậy, tôi cần tra cứu phần phía đông.Hành động 2 Tracứu[phần phía đông]Quan sát 2 (Kết quả 1 / 1) Phần phía đông kéo dài đến Cao nguyên và được gọi là tạo núi Đồng bằng Trung tâm.Suy nghĩ 3 Phần phía đông của tạo núi Colorado kéo dài đến Cao nguyên. Vì vậy, tôi cần tìm kiếm Cao nguyên và tìm phạm vi độ cao của nó.Hành động 3 Tìmkiếm[Vùng Cao]Quan sát 3 Vùng Cao đề cập đến một trong hai vùng đất riêng biệtSuy nghĩ 4 Thay vào đó, tôi cần tìm kiếm Vùng Cao (Hoa Kỳ).Hành động 4 Tìmkiếm[Vùng Cao (Hoa Kỳ)]Quansát 4 VùngCaolà mộttiểuvùngcủa ĐạiBìnhnguyên. Từ đôngsangtây, vùngCaocaotăngdần độ caotừ khoảng 1.800 đến 7.000ft (550 đến 2.130m).[3]Suy nghĩ 5 Vùng Cao tăng dần độ cao từ khoảng 1.800 đến 7.000 ft, vì vậy đáp án là 1.800 đến 7.000 ft....
Lưu ý rằng các thiết lập lời nhắc khác nhau được sử
dụng cho các loại nhiệm vụ khác nhau. Đối với các nhiệm vụ mà suy luận
là yếu tố quan trọng hàng đầu (ví dụ: HotpotQA), nhiều bước suy
nghĩ-hành động-quan sát được sử dụng cho lộ trình giải quyết nhiệm vụ.
Đối với các nhiệm vụ ra quyết định bao gồm nhiều bước hành động, suy
nghĩ được sử dụng ít hơn.
Bài báo đầu tiên
đánh giá ReAct trong các nhiệm vụ suy luận chuyên sâu về kiến thức như
trả lời câu hỏi (HotPotQA) và xác minh sự thật (Fever). PaLM-540B được sử dụng làm mô hình cơ sở cho việc nhắc.
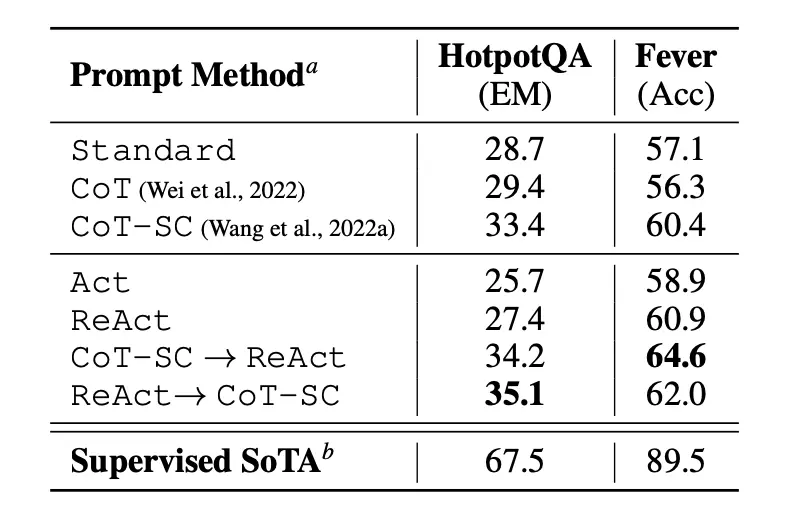
Kết quả của lời nhắc trong HotPotQA và Fever khi sử
dụng các phương pháp nhắc khác nhau cho thấy ReAct nhìn chung hoạt động
tốt hơn Act (chỉ bao gồm hành động) ở cả hai nhiệm vụ.
Chúng ta cũng có thể thấy ReAct hoạt động tốt hơn CoT
trên Fever và chậm hơn CoT trên HotpotQA. Bài báo đã cung cấp một phân
tích lỗi chi tiết. Tóm lại:
CoT bị ảo giác thực tế
Ràng buộc về cấu trúc của ReAct làm giảm tính linh hoạt trong việc xây dựng các bước suy luận
ReAct phụ thuộc rất nhiều vào thông tin mà nó đang
thu thập; kết quả tìm kiếm không cung cấp thông tin sẽ làm chệch hướng
suy luận của mô hình và dẫn đến khó khăn trong việc khôi phục và định
hình lại các ý tưởng.
Các phương pháp lời nhắc kết hợp và hỗ trợ chuyển đổi
giữa ReAct và CoT + Tự nhất quán thường hoạt động tốt hơn tất cả các
phương pháp lời nhắc khác.
Kết quả trong các Nhiệm vụ Ra quyết định
Bài báo cũng báo cáo các kết quả chứng minh hiệu suất
của ReAct trong các nhiệm vụ ra quyết định. ReAct được đánh giá dựa
trên hai tiêu chuẩn là ALFWorld (trò chơi dựa trên văn bản) và WebShop
(môi trường trang web mua sắm trực tuyến). Cả hai đều liên quan đến các
môi trường phức tạp đòi hỏi khả năng suy luận để hành động và khám phá
hiệu quả.
Lưu ý rằng các lời nhắc ReAct được thiết kế khác nhau
cho các nhiệm vụ này nhưng vẫn giữ nguyên ý tưởng cốt lõi là kết hợp
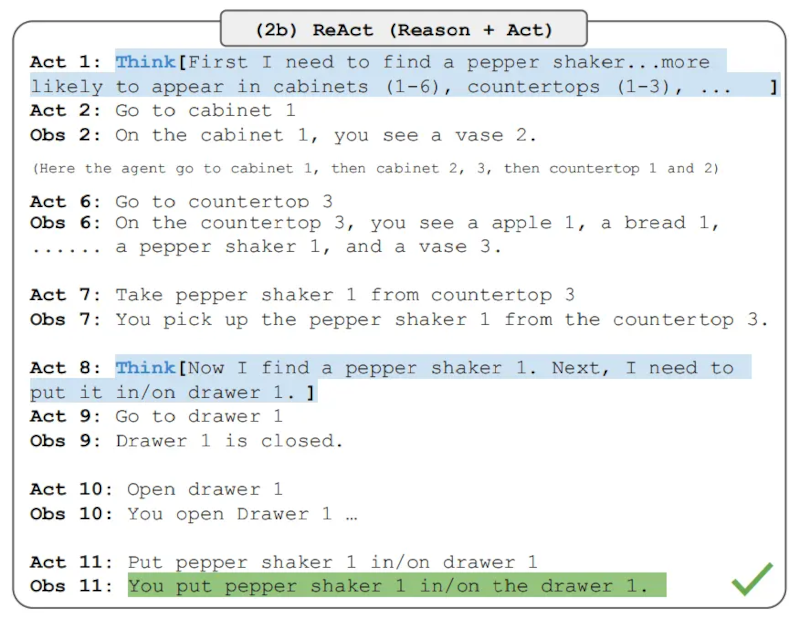
suy luận và hành động. Dưới đây là một ví dụ về bài toán ALFWorld liên
quan đến lời nhắc ReAct.
ReAct vượt trội hơn Act trên cả ALFWorld và Webshop.
Hành động, nếu không có tư duy, sẽ không thể phân tích chính xác các mục
tiêu thành các mục tiêu con. Suy luận dường như có lợi thế trong ReAct
cho các loại nhiệm vụ này, nhưng các phương pháp dựa trên lời nhắc hiện
tại vẫn còn kém xa hiệu suất của con người chuyên nghiệp trong các nhiệm
vụ này.
Xem bài báo để biết kết quả chi tiết hơn.
Sử dụng LangChain ReAct
Dưới đây là một ví dụ cụ thể về cách thức hoạt động
của phương pháp gợi ý ReAct trong thực tế. Chúng tôi sẽ sử dụng OpenAI
cho LLM và LangChain vì nó đã có sẵn chức năng tích hợp tận dụng khung
ReAct để xây dựng các tác nhân thực hiện nhiệm vụ bằng cách kết hợp sức
mạnh của LLM và các công cụ khác nhau.
Trước tiên, hãy cài đặt và nhập các thư viện cần thiết:
%%capture# cập nhật hoặc cài đặt các thư viện cần thiết!pip install --upgrade openai!pip install --upgrade langchain!pip install --upgrade python-dotenv!pip install google-search-results# Nhập khẩu các thư việnimport openaiimport osfrom langchain.llms import OpenAIfrom langchain.agents import load_toolsfrom langchain.agents import initialize_agentfrom dotenv import load_dotenvload_dotenv()# tải lên các khóa API; bạn sẽ cần lấy những khóa này nếu chưa cóos.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")os.environ["SERPER_API_KEY"] = os.getenv("SERPER_API_KEY")
Bây giờ chúng ta có thể cấu hình LLM, các công cụ chúng ta sẽ sử dụng và
tác nhân cho phép chúng ta tận dụng khung ReAct cùng với LLM và các
công cụ. Lưu ý rằng chúng ta đang sử dụng API tìm kiếm để tìm kiếm thông
tin bên ngoài và LLM như một công cụ toán học.
Sau khi cấu hình xong, chúng ta có thể chạy tác nhân
với truy vấn/lời nhắc mong muốn. Lưu ý rằng ở đây chúng ta không cần
cung cấp các ví dụ ít ỏi như đã giải thích trong bài báo.
agent.run("Bạn trai của Olivia Wilde là ai? Tuổi hiện tại của anh ấy là bao nhiêu lũy thừa 0,23?")
Chuỗi thực hiện trông như sau:
> Nhập vào chuỗi AgentExecutor mới...Tôi cần tìm ra bạn trai của Olivia Wilde là ai và sau đó tính tuổi của anh ấy lũy thừa 0,23.Hành động: Tìm kiếmĐầu vào hành động: “bạn trai của Olivia Wilde"Quan sát thấy: Olivia Wilde bắt đầu hẹn hò với Harry Styles sau khi chấm dứt mối quan hệ kéo dài nhiều năm với Jason Sudeikis — xem dòng thời gian mối quan hệ của họ.Suy luận: Tôi cần tìm ra tuổi của Harry StylesHành động: Tìm kiếmĐầu vào hành động: “Tuổi của Harry Styles”Quan sát thấy: 29 tuổiSuy luận: Tôi cần tính 29 lũy thừa 0,23Hành động: Tính toánĐầuvàohành động:29^0.23Quan sát thấy: Đáp án: 2.169459462491557Suy luận: Giờ tôi đã biết đáp án cuối cùng.Câu trả lời cuối cùng: Harry Styles, bạn trai của Olivia Wilde, 29 tuổi và tuổi của anh ấy lũy thừa 0,23 là 2,169459462491557. > Chuỗi đã hoàn thành.
Kết quả đầu ra chúng ta nhận được như sau:
"Harry Styles, bạn trai của Olivia Wilde, 29 tuổi và tuổi của anh ấy lũy thừa 0,23 là 2,169459462491557."
Chúng tôi đã điều chỉnh ví dụ từ tài liệu LangChain, vì vậy công lao thuộc về họ. Chúng tôi khuyến khích người học khám phá các cách kết hợp công cụ và nhiệm vụ khác nhau.
Yao
et al., 2022 introduced a framework named ReAct where LLMs are
used to generate both reasoning
traces and
task-specific actions
in an interleaved manner.
Generating
reasoning traces allow the model to induce, track, and update action
plans, and even handle exceptions. The action step allows to
interface with and gather information from external sources such as
knowledge bases or environments.
The ReAct
framework can allow LLMs to interact with external tools to retrieve
additional information that leads to more reliable and factual
responses.
Results show
that ReAct can outperform several state-of-the-art baselines on
language and decision-making tasks. ReAct also leads to improved
human interpretability and trustworthiness of LLMs. Overall, the
authors found that best approach uses ReAct combined with
chain-of-thought (CoT) that allows use of both internal knowledge and
external information obtained during reasoning.
How
it Works?
ReAct is
inspired by the synergies between "acting" and "reasoning"
which allow humans to learn new tasks and make decisions or
reasoning.
Chain-of-thought
(CoT) prompting has shown the capabilities of LLMs to carry out
reasoning traces to generate answers to questions involving
arithmetic and commonsense reasoning, among other tasks (Wei
et al., 2022). But its lack of access to the external world or
inability to update its knowledge can lead to issues like fact
hallucination and error propagation.
ReAct is a
general paradigm that combines reasoning and acting with LLMs. ReAct
prompts LLMs to generate verbal reasoning traces and actions for a
task. This allows the system to perform dynamic reasoning to create,
maintain, and adjust plans for acting while also enabling interaction
to external environments (e.g., Wikipedia) to incorporate additional
information into the reasoning. The figure below shows an example of
ReAct and the different steps involved to perform question answering.
In the example
above, we pass a prompt like the following question from HotpotQA:
Aside
from the Apple Remote, what other devices can control the program
Apple Remote was originally designed to interact with?
Note that
in-context examples are also added to the prompt but we exclude that
here for simplicity. We can see that the model generates task
solving trajectories
(Thought, Act). Obs corresponds to observation from the environment
that's being interacted with (e.g., Search engine). In essence, ReAct
can retrieve information to support reasoning, while reasoning helps
to target what to retrieve next.
ReAct
Prompting
To demonstrate
how ReAct prompting works, let's follow an example from the paper.
The first step
is to select cases from a training set (e.g., HotPotQA) and compose
ReAct-format trajectories. These are used as few-shot exemplars in
the prompts. The trajectories consist of multiple
thought-action-observation steps as shown in the figure above. The
free-form thoughts are used to achieve different tasks such as
decomposing questions, extracting information, performing
commonsense/arithmetic reasoning, guide search formulation, and
synthesizing final answer.
Here is an
example of what the ReAct prompt exemplars look like (obtained from
the paper and shortened to one example for simplicity):
Question What is the elevation range for the area that the eastern sector of theColorado orogeny extends into?Thought 1 I need to search Colorado orogeny, find the area that the eastern sectorof the Colorado orogeny extends into, then find the elevation range of thearea.Action 1 Search[Colorado orogeny]Observation 1 The Colorado orogeny was an episode of mountain building (an orogeny) inColorado and surrounding areas.Thought 2 It does not mention the eastern sector. So I need to look up easternsector.Action 2 Lookup[eastern sector]Observation 2 (Result 1 / 1) The eastern sector extends into the High Plains and is calledthe Central Plains orogeny.Thought 3 The eastern sector of Colorado orogeny extends into the High Plains. So Ineed to search High Plains and find its elevation range.Action 3 Search[High Plains]Observation 3 High Plains refers to one of two distinct land regionsThought 4 I need to instead search High Plains (United States).Action 4 Search[High Plains (United States)]Observation 4 The High Plains are a subregion of the Great Plains. From east to west, theHigh Plains rise in elevation from around 1,800 to 7,000 ft (550 to 2,130m).[3]Thought 5 High Plains rise in elevation from around 1,800 to 7,000 ft, so the answeris 1,800 to 7,000 ft.Action 5 Finish[1,800 to 7,000 ft]...
Note that different prompts setups
are used for different types of tasks. For tasks where reasoning is
of primary importance (e.g., HotpotQA), multiple
thought-action-observation steps are used for the task-solving
trajectory. For decision making tasks involving lots of action steps,
thoughts are used sparsely.
Results on Knowledge-Intensive
Tasks
The paper first
evaluates ReAct on knowledge-intensive reasoning tasks such as
question answering (HotPotQA) and fact verification (Fever).
PaLM-540B is used as the base model for prompting
The prompting
results on HotPotQA and Fever using different prompting methods show
that ReAct generally performs better than Act (involves acting only)
on both tasks.
We can also
observe that ReAct outperforms CoT on Fever and lags behind CoT on
HotpotQA. A detailed error analysis is provided in the paper. In
summary:
CoT suffers
from fact hallucination
ReAct's
structural constraint reduces its flexibility in formulating
reasoning steps
ReAct
depends a lot on the information it's retrieving; non-informative
search results derails the model reasoning and leads to difficulty
in recovering and reformulating thoughts
Prompting
methods that combine and support switching between ReAct and
CoT+Self-Consistency generally outperform all the other prompting
methods.
Results
on Decision Making Tasks
The paper also
reports results demonstrating ReAct's performance on decision making
tasks. ReAct is evaluated on two benchmarks called ALFWorld
(text-based game) and WebShop
(online shopping website environment). Both involve complex
environments that require reasoning to act and explore effectively.
Note that the
ReAct prompts are designed differently for these tasks while still
keeping the same core idea of combining reasoning and acting. Below
is an example for an ALFWorld problem involving ReAct prompting.
ReAct
outperforms Act on both ALFWorld and Webshop. Act, without any
thoughts, fails to correctly decompose goals into subgoals. Reasoning
seems to be advantageous in ReAct for these types of tasks but
current prompting-based methods are still far from the performance of
expert humans on these tasks.
Check out the
paper for more detailed results.
LangChain
ReAct Usage
Below is a
high-level example of how the ReAct prompting approach works in
practice. We will be using OpenAI for the LLM and LangChain as it
already has built-in functionality that leverages the ReAct framework
to build agents that perform tasks by combining the power of LLMs and
different tools.
First, let's
install and import the necessary libraries:
%%capture# update or install the necessary libraries!pip install --upgrade openai!pip install --upgrade langchain!pip install --upgrade python-dotenv!pip install google-search-results# import librariesimport openaiimport osfrom langchain.llms import OpenAIfrom langchain.agents import load_toolsfrom langchain.agents import initialize_agentfrom dotenv import load_dotenvload_dotenv()# load API keys; you will need to obtain these if you haven't yetos.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")os.environ["SERPER_API_KEY"] = os.getenv("SERPER_API_KEY")
Now we can configure the LLM, the
tools we will use, and the agent that allows us to leverage the ReAct
framework together with the LLM and tools. Note that we are using a
search API for searching external information and LLM as a math tool.
Once that's configured, we can now
run the agent with the desired query/prompt. Notice that here we are
not expected to provide few-shot exemplars as explained in the paper.
agent.run("Who is Olivia Wilde's boyfriend? What is his current age raised to the 0.23 power?")
The chain execution looks as
follows:
> Entering new AgentExecutor chain...I need to find out who Olivia Wilde's boyfriend is and then calculate his age raised to the 0.23 power.Action: SearchAction Input: "Olivia Wilde boyfriend"Observation: Olivia Wilde started dating Harry Styles after ending her years-long engagement to Jason Sudeikis — see their relationship timeline.Thought: I need to find out Harry Styles' age.Action: SearchAction Input: "Harry Styles age"Observation: 29 yearsThought: I need to calculate 29 raised to the 0.23 power.Action: CalculatorAction Input: 29^0.23Observation: Answer: 2.169459462491557Thought: I now know the final answer.Final Answer: Harry Styles, Olivia Wilde's boyfriend, is 29 years old and his age raised to the 0.23 power is 2.169459462491557.> Finished chain.
The output we get is as follows:
"Harry Styles, Olivia Wilde's boyfriend, is 29 years old and his age raised to the 0.23 power is 2.169459462491557."
We adapted the example from the
LangChain
documentation, so credit goes to them. We encourage the learner
to explore different combination of tools and tasks.