Introducing
the Linked Commons
By Maria Belen Guaranda,
January 23, 2020
Bài được
đưa lên Internet ngày: 23/01/2020
Đây
là phần của
loạt bài đăng giới thiệu các dự án được những
người đóng góp nguồn mở xây dựng và được Creative
Commons hướng dẫn trong quá trình cuộc thi Lập trình Mùa
hè của Google năm 2019 - Google
Summer of Code (GSoC) 2019. Maria Belen Guaranda là một trong
những người đóng góp và chúng tôi biết ơn vì công
việc của cô trong dự án này.
“
Bằng
việc trực quan hóa thông tin, chúng tôi biến nó thành một
bức tranh để bạn có thể khai thác bằng đôi mắt của
bạn”.
David
McCandless
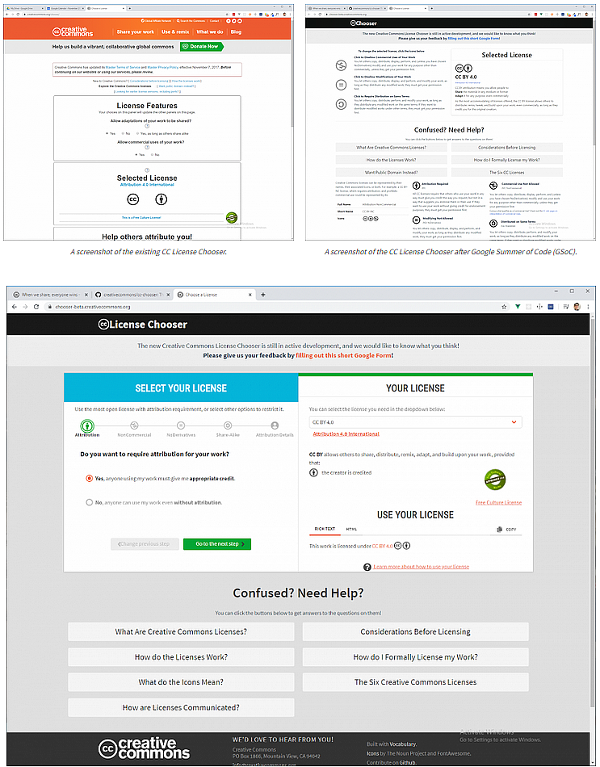
Bức
tranh nội dung được cấp phép mở là
rộng lớn và đa dạng. Hàng triệu
trang web đặt chỗ và chia sẻ các tác phẩm được cấp
phép CC - trên thực tế, chúng tôi ước tính có hơn 1,6
tỷ khắp trên web! Với sự tăng trưởng này các
tác phẩm được cấp phép CC, Creative Commons (CC) đang ngày
càng được quan tâm trong việc học cách để đặt chỗ
và những người sử dụng các tư liệu được cấp phép
CC được kết nối, cũng như các dạng nội dung được
xuất bản theo một giấy phép CC và cách thức nội dung
này được chia sẻ. Mỗi tháng, CC sử dụng dữ liệu
Common
Crawl để tìm kiếm tất cả các miền có chứa nội
dung được cấp phép CC. Tập hợp dữ
liệu này gồm thông tin về địa chỉ web URL của các
website và các giấy phép được sử dụng.
Để đưa ra các kết luận và sự thấu
hiểu từ tập hợp dữ liệu này, chúng tôi đã tạo ra
Cái chung được Liên kết (
Linked
Commons): sự trực quan hóa chỉ ra cách Cái chung được
Liên kết dạng số như thế nào.
Trong Linked Commons, các nút (các đơn vị
trong một cấu trúc dữ liệu) đại diện cho các website
của một tổ chức, con người, cơ sở hàn lâm, .v.v.
Đường liên kết giữa các nút tồn tại nếu một
website đặt chỗ nội dung được cấp phép CC thuộc về
hoặc được đặt chỗ bởi một website khác (như được
một đường liên kết URL chỉ ra). Cộng đồng đại diện
cho nhóm các website có liên quan chặt chẽ với nhau vì họ
sản xuất và/hoặc chia sẻ nội dung giữa họ với nhau.
Lượng dữ liệu khổng lồ làm cho bất
kỳ trình duyệt web nào trả về các yếu tố thành phần
chậm và có thể thậm chí treo. Vì 100 ngàn nút bao gồm
trong Linked Commons, sự trực quan đó ban đầu mất nhiều
thời gian để trả về và đã có xuất hiện bị phân
mảnh - điều này từng là mối lo ngại chính.
Điều đó giải thích vì sao chúng tôi đã
quyết định sử dụng dữ liệu từ chỉ một tháng duy
nhất và chọn 500 website hàng đầu có chứa các đường
liên kết tới tư liệu được cấp phép CC, cũng như tất
cả các miễn khác mà 500 nút đó được kết nối tới.
Bổ sung thêm vào việc làm giảm thời gian tải, chúng tôi
thấy điều này cũng là thân thiện với người sử dụng
vì việc điều hướng đồ họa của toàn bộ tập hợp
dữ liệu có thể là chóng mặt. Thậm chí với tập hợp
dữ liệu nhỏ hơn này, chúng tôi đã có khả năng thu
thập những thấu hiểu đáng giá từ hình đồ họa đó,
bao gồm việc phát hiện các cộng đồng con các máy chủ
và những người sử dụng giấy phép CC. Một cộng đồng
con như vậy được chỉ ra trong hình bên dưới.
Cộng đồng con ở trên
là một cộng đồng “giáo dục”; được hình thành từ
các thư viện, các
trường đại học, và
các trường phổ thông.
Các trực quan hóa như vậy là đáng giá
cho CC vì chúng có thể giúp hướng dẫn các nỗ lực vươn
ra ngoài của chúng tôi và cho các truyền thông có nhắm
đích. Đội Tìm kiếm CC (
CC
Search) cũng có thể sử dụng dữ liệu này để chọn
các lĩnh vực nào ưu tiên đánh chỉ mục trong Catalog của
CC.
Trực quan hóa là có tính tương tác; những
người sử dụng có thể xoay, phóng to và thu nhỏ, hơ
chuột qua nút để thấy các láng giềng của nó, và nhấn
vào nút để hiển thị đồ thị dạng bánh, giống như
ảnh bên dưới. Chúng tôi khuyến khích những người sử
dụng kiểm thử Linked Commons và xem những thấu hiểu nào
họ có thể thu thập được từ thông tin này!
Tiếp theo là gì?
Chúng
tôi có kế hoạch tiếp tục làm việc về Linked Commons.
Đây là vài tính năng chúng tôi hy vọng bổ
sung thêm:
-
Cập nhật sống động - Đồ
họa đó hiện là tĩnh vì nó sử dụng tệp dữ liệu
của chỉ một tháng duy nhất đã được xử lý. Chúng
tôi muốn cập nhật tự động đồ họa đó ngay khi dữ
liệu mới được xử lý.
-
Lọc
các miền theo quốc gia
- Vài miền có các hậu tố đại diện
cho các quốc gia, như domain.au tương
ứng với miền từ nước Úc. Chúng tôi có kế hoạch sử
dụng các hậu tố đó để lọc các nút trong sự trực
quan hóa theo quốc gia.
-
Lọc các miền theo tên - Người
sử dụng có thể muốn kiểm tra liệu miền nhất định
nào đó có nội dung được cấp phép CC và nội dung đó
được sử dụng như thế nào. Chúng tôi có kế hoạch
bổ sung thêm thanh tìm kiếm và cung cấp cho người sử
dụng khả năng tìm kiếm nút nhất định nào đó nếu
biết tên miền và/hoặc URL.
Hãy cho chúng tôi phản hồi của bạn!
Linked
Commons là dự án nguồn mở. Mã nguồn của dự án là sẵn
sàng trong kho
Github.
Những đóng góp được chào đón! Các chi tiết kỹ thuật
về dự án này đã được phát triển như thế nào, vui
lòng đọc loạt
bài đăng này trên blog
CC Open Source.
This
is part of a series of posts introducing the projects built by open
source contributors mentored by Creative Commons during Google
Summer of Code (GSoC) 2019. Maria Belen Guaranda was one of those
contributors and we are grateful for her work on this project.
“By
visualizing information, we turn it into a landscape that you can
explore with your eyes.” David McCandless
The
landscape of openly licensed content is wide and varied. Millions of
web pages host and share CC-licensed works—in fact, we estimate
that there are over 1.6 billion across the web! With this growth of
CC-licensed works, Creative Commons (CC) is increasingly interested
in learning how hosts and users of CC-licensed materials are
connected, as well as the types of content published under a CC
license and how this content is shared. Each month, CC uses Common
Crawl
data
to find all domains that contain CC-licensed content. This dataset
contains information about the URL of the websites and the licenses
used.
Using the
Linked Commons
In order to draw
conclusions and insights from this dataset, we created the Linked
Commons: a visualization that shows how the Commons is digitally
connected.
In the Linked
Commons, nodes (units in a data structure) represent websites of an
organization, person, academic institution, etc. A link between nodes
exists if one website hosts CC-licensed content that belongs to or is
hosted by another website (as indicated by a URL link). A community
represents a group of websites that are closely related to each other
because they produce and/or share CC-licensed content between them.
Vast quantities
of data make any web browser render elements slowly and may
eventually freeze. Due to the 100k nodes included in the Linked
Commons, the visualization initially took a long time to render and
had a clustered appearance—this was a major concern.
That’s why we
decided to use data from only a single month and chose the top 500
websites containing links to CC-licensed material, as well as all of
the other domains those 500 nodes are connected to. In addition to
lessening the loading time, we found that this was also more
user-friendly because navigating the entire dataset’s graph would
be dizzying. Even with this smaller dataset, we were able to gather
valuable insights from the graph, including discovering
subcommunities of CC license hosts and users. One such subcommunity
is shown in the image below.
The subcommunity
above is an “educational” community; made up of libraries,
universities, and schools.
Visualizations
like these are valuable for CC because they can help guide our
outreach efforts and targeted communications. The CC
Search team can also use this data to choose which domains to
prioritize indexing in the CC Catalog.
The
visualization is interactive; users can pan, zoom in and out, hover
over a node to see its neighbors, and click on a node to display a
pie chart, like the one below. We encourage users to test out the
Linked Commons and see what insights they can gather from this
information!
What’s
next?
We plan to
continue working on the Linked Commons. Here are some features we
hope to add:
Give us
your feedback!
The
Linked Commons is an open source project. The project’s source code
is available in the
Github
repo.
Contributions are welcome! For the technical details of how this
project was developed, please read this series
of posts on the CC
Open Source blog.
Dịch: Lê Trung Nghĩa
letrungnghia.foss@gmail.com